
- Mémoire flash : 64ko
- Mémoire SRAM : 20ko
- Vin :2,0-3.6V
- Résolution des entrées :4096
- Tension de sortie :3V3 (maxi 300mA)
- Interface Ressources:2x SPI, 3x USART, 2x I2C, 1x CAN, 37x I/O ports,
- convertisseur Analogique-numérique :2x ADC (12 bits/10 canaux)
- Minuteries:3 général minuteries et 1 minuterie avancée
- bits (mode ARM)
- 16 bits (mode THUMB)
- mixte 32/16 bits (mode THUMB 2)
- Imm : 8 bits (0→0xFF)
- Rs : 4 bits pour un décalage circulaire (valeurs paires de 0 à 30)
- IA pour la post-incrémentation (Increment After)
- IB pour la pré-incrémentation (Increment Before)
- DA pour la post-décrémentation (Decrement After)
- DB pour la pré-décrémentation (Decrement Before)
- FD : Full Descending
- FA : Full Ascending
- ED : Empty Descending
- EA : Empty Ascending
- B adresse → Aller à l’adresse
- BX registre → Aller à l’adresse pointée par le registre et éventuellement changer de mode (ARM/THUMB interworking) Ces instructions modifient le compteur programme pc (r15)
- BL(X) → Pour sauvegarder l’adresse de retour dans lr (r14) L’adresse de retour est celle de l’instruction suivant le BL. Pour revenir d’un branchement BL il suffit de remettre lr dans pc
- BX lr
- MOV pc,lr (deprecated)
- EQ Equal Z == 1
- NE Not equal Z == 0
- CS HS Carry set/unsigned higher or same C == 1
- CC LO Carry clear/unsigned lower C == 0
- MI Minus/negative N == 1
- PL Plus/positive or zero N == 0
- VS Overflow V == 1
- VC No overflow V == 0
- HI Unsigned higher C == 1 and Z == 0
- LS Unsigned lower or same C == 0 or Z == 1
- GE Signed greater than or equal N == V
- LT Signed less than N != V
- GT Signed greater than Z == 0 and N == V
- LE Signed less than or equal Z == 1 or N != V
- Instructions supprimées.
Quelques instructions ont été coupées. Parmi les diverses instructions de multiplication, il ne reste que les restes mul, les soustractions inversées (rsb, rsc), de même que les instructions de permutation et de coprocesseur, mais elles sont rares de toute façon. - «Nouvelles» instructions.
Les codes mnémoniques sont nouveaux, mais ce ne sont en réalité que des cas spéciaux d’instructions ARM classiques. THUMB a des opcodes shift/rotation distincts: lsl, lsr, asr et ror, qui correspondent, fonctionnellement, à «mov Rd, Rm, Op2».
Il existe également un neg Rd, Rm pour Rd = 0-Rm, essentiellement un rsb.
Et je suppose que vous pouvez appeler un nouveau push et pop , car ils n'apparaissent pas comme des codes ARM dans certains devkits. >
- Sans conditiins.
Sauf en branche. Bonjour, étiquetage gratuit: \. - taille du transfer : B, H, D pour 8 bits (Byte), 16 bits (Half-word), 64 bits (Double-word)
(Attention : conflit avec la notation Microsoft utilisée par Keil : WORD = 16 bits, DWORD = 32 bits)
SB, SH pour les extensions de signe à 32 bits,
16 pour opération effectuée en parallèle sur les deux moitiés d'un mot de 32 bits - mise a jour optionnelle des flags : S
- incrémentation ou décrémentation pour les Load et Store Multiples LDM et STM :
- IA : Increment After
- DB : Decrement Before
- codes de condition sur 2 caractères :
EQ Z = 1 Equal NE Z = 0 Not equal HI C = 1 and Z = 0 Higher unsigned CS or HS C = 1 Higher or same unsigned LS C = 0 or Z = 1 Lower or same unsigned CC or LO C = 0 Lower unsigned MI N = 1 Negative signed PL N = 0 Positive or zero signed VS V = 1 Overflow signed VC V = 0 No overflow signed GT Z = 0 and N = V Greater than signed GE N = V Greater than or equal signed LE Z = 1 or N != V Less than or equal signed LT N != V Less than signed - forçage de taille pour le codage instruction
- .W : forcer 32 bits "Wide" (si disponible)
- .N : forcer 16 bits "Narrow" (si possible)
- constante ou expression constante (signe '#')
MOV r0, #0x4F ; hexa MOV r1, #112 ; decimal MOV r2, #(12*3+5) ; expression calculee pendant l'assemblage
Attention aux limitations dues au codage sur 12 bits
- constante de 32 bits en 2 opérations
MOV r0, #0x2013 ; 0x00002013 dans r0 (imm16) MOVT r0, #0x1963 ; 0x19632013 dans r0 (imm16)
- macro LDR et litteral pool (signe '=')
LDR r0, =0x19632013
L'assembleur va soit remplacer cette pseudo-instruction (macro) par 1 MOV, ou 1 MOV et 1 MOVT, ou un adressage relatif-PC en ayant mis la constante dans la mémoire programme, dans une zone dite "litteral pool". - Simple :
MOV r0, r1 ; copie de r1 dans r0
- Avec décalage ou rotation du registre source :
MOV r0, r1, LSL #4 ; copie de r1, décalé de 4 bits a gauche, dans r0 MOV r0, r1, LSR r5 ; copie de r1, décalé de r5 bits a droite, dans r0 MOV r0, r1, RRX ; copie de r1, avec rotation a droite de 1 bit, dans r0
Note : on pourrait donc se passer des instructions LSL, LSR, ASR, ROR, RRX...LSL Logic Shift Left LSR Logic Shift Right (unsigned) ASR Arithmetic Shift Right (sign extension) ROR Rotate Right over 32 bits RRX Rotate Right 1 place over 33 bits (C flag included)
Rappel : les décalages permettent de faire des multiplications et divisions par les puissances de 2 très efficacement.
- Multiplications
MUL r3, r0, r1 ; le produit r0 * r1 tronqué à 32 bits est mis dans r3 SMULL r2, r3, r0, r1 ; le produit r0 * r1 signé sur 64 bits est mis dans la paire r2, r3 (little endian) UMULL r2, r3, r0, r1 ; idem en non-signé
- Multiplication-Accumulation
MLA r3, r0, r1, r2 ; la somme r2 + r0*r1 tronquée à 32 bits est mis dans r3 SMLAL r2, r3, r0, r1 ; le produit r0 * r1 signé sur 64 bits est ajouté au contenu de la paire r2, r3 UMLAL r2, r3, r0, r1 ; idem en non-signé
- 1 registre
LDR r1, [r7] ; les crochets '[' et ']' signalent l'indirection
- 2 registres ("pre-indexed"), le second (index) peut être décalé à gauche
LDR r1, [r6, r7] ; adresse = r6 + r7, par exemple base + index LDR r1, [r6, r7, LSL #2] ; adresse = r6 + r7 * 4 LDR r1, [r6, r7]! ; le '!' signale mise a jour de r6 = r6 + r7
Note : dans le 3eme cas, r7 est un incrément plutôt qu'un index, c'est pour parcourir un tableau séquentiellement. - 1 registre + 1 constante (déplacement ou offset signé)
LDR r1, [r6, #120] ; acces à un membre d'une structure ou objet C++ LDR r1, [r6, #4]! ; pré-indexation, le '!' signale mise a jour de r6 = r6 + 4 LDR r1, [r6], #4 ; post-indexation, adresse = r6, puis r6 = r6 + 4
Note : dans le 2eme et le 3eme cas, la constante est un decrément plutôt qu'un index, c'est pour parcourir un tableau séquentiellement:r1 = *(++r6) // en C r1 = *(r6++)
- application particulière : adressage relatif-PC pour une donnée en ROM
Dans le cas d'un code relogeable, ni l'adresse associée à un label ni celle de l'instruction courante ne sont connues au moment de l'assemblage, mais la différence l'est :labul dcd 0x0561559513 ... LDR r0, [PC, #(labul-.-4)] ; copie dans r0 la variable labul stockée en ROM LDR r0, labul ; forme abrégée, émulation d'adressage direct
Le point représente l'adresse de l'instruction courante, au moment de l'exécution de l'instruction, PC contient déjà cette adresse +4, donc l'expression constante (labul-.-4) est ce qu'il faut ajouter à PC pour accéder à la donnée.
Cette technique est utilisée pour le "litteral pool" (macro LDR avec sign '=') - Load/Store Multiples (par dérogation au style RISC)
Attention : la syntaxe de ces instructions n'est pas cohérente avec le reste du jeu d'instructions.LDM r7, {r0, r1, r2, r4} ; charger les registres de la liste avec les valeurs lues en mémoire, adr. de base r7 LDM r7!, {r0, r1, r2, r4} ; idem, puis mettre a jour r7 STM r7, {r0, r1, r2, r4} ; stocker le contenu des registres de la liste en mémoire, adr. de base r7 STM r7!, {r0, r1, r2, r4} ; idem, puis mettre a jour r7Ces instructions acceptent les suffixes DB (Decrement Before) et IA (Increment After), qui est le choix par défaut.
La liste de registres entres accolades '{' et '}' peut contenir 1 à 15 registres (tous sauf SP).
Attention : l'ordre des registres stockés ou lus en mémoire par une instruction multiple est toujours tel que les adresses mémoire croissent dans le sens des indices des registres (c'est indépendant de l'ordre des éléments de la liste, qui est ignoré). - Push et Pop
L'empilage (Push) et le dépilage (Pop) sont des applications de Store Multiple et Load Multiple avec SP et '!'PUSH {r1, r2} ; empiler r1 et r2 (r2 en premier, c'est a dire à l'adresse la plus élevée) STMDB SP!, {r1, r2} ; idem, DB choisi pour "full descending stack" POP {r1, r2} ; dépiler r1 et r2 (r2 en dernier, c'est a dire de l'adresse la plus élevée) LDM SP!, {r1, r2} ; idem, IA choisi pour "full descending stack"Le dépilage de PC est équivalent à un saut indirect utilisant une valeur prise dans la pile, ce qui peut tenir lieu de retour de sous-programme à condition d'avoir empilé LR en début de sous-programme. On peut en profiter pour empiler quelques registres :
PUSH {r4, r5, r6, LR} ; au début du sous-programme ... ... POP {r4, r5, r6, PC} ; retour du sous-programme - Le X signifie indirect par registre.
- Retour de sous programme : contrairement à la majorité des autres architectures, l'ARM n'a pas d'intruction spécifique, le retour se fait avec BX LR si l'adresse de retour est dans LR, ou POP {PC] si elle est dans le pile.
- Retour d'interruption : contrairement à la majorité des autres architectures, l'ARM n'a pas d'intruction spécifique,
le retour d'interruption se code comme un retour de sous-programme ordinaire, c'est à la place de l'adresse de retour qu'il y a
un code spécifique (0xFFFFFFFx) pour activer le traitement approprié aux interruptions
(dépilage r0, r1, r2, r3, r12, LR, PC, xPSR) - le nombre de lettres après le I détermine le nombre d'instructions concernées
- les lettres permises sont T (Then) et E (Else), la première est toujours T
- l'instruction IT prend comme argument 1 code condition parmi les 14 possibles
- chaque instruction associée à un T sera exécutée si la condition est vraie
- chaque instruction associée à un E sera exécutée si la condition n'est pas vraie
- L'assembleur génère l'instruction IT lui-même, on peut l'omettre du code source
- Chaque instruction du bloc IT est doit être munie d'un suffixe indiquant la condition qui doit lui être appliquée

Il est à noter que pour programmer la carte, il faut déplacer manuellement le jumper BOOT0 à la position 1 pour entrer en mode de programmation, et le repositionner sur la position 0 pour revenir au mode de fonctionnement normal.
Caractéristiques de l’ARM
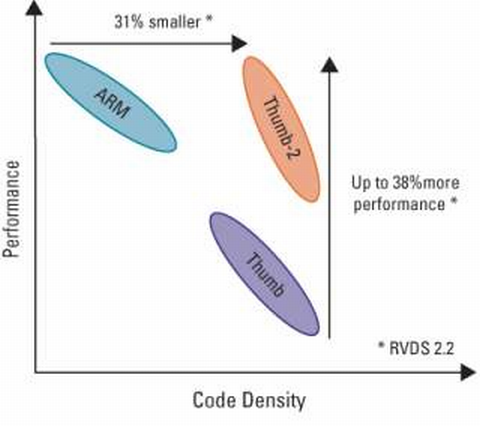
Historiquement les instructions faisaient toutes 32 bits.Pour rendre le code plus compact et permettre des réductionsde coûts, des jeux d’instructions simplifiés ont été ajoutés :Les instructions font :
Les registres
16 registres généraux et 3 registres avec des rôles particuliers :| r0 | r1 | r2 | r3 | r4 | r5 | r6 | r7 | r8 | r9 | r10 | r11 | r12 | r13(sp) : Stack pointer (pointeur de pile) | r14(lr) : Link register (adresse de retour) | r15(pc) : Compteur programme |
Jeu d’instructions
On peut classer les instructions en trois grandes catégories :Traitement et manipulation des données :
Opérations Arithmétiques et logiques
OPE r_dest, r_s1, r_s2
Exemples
AND r0,r1,r2 ;pour (r0=r1&r2)
ADD r5,r1,r5 ;pour (r5=r1+r5)
Les instructions
ADD r0,r1,r2 ;→ r0=r1+r2 Addition
ADC r0,r1,r2 ;→ r0=r1+r2+C Addition avec retenue
SUB r0,r1,r2 ;→ r0=r1-r2 Soustraction
SBC r0,r1,r2 ;→ r0=r1-r2-C+1 Soustraction avec retenue
RSB r0,r1,r2 ;→ r0=r2-r1 Soustraction inversée
RSC r0,r1,r2 ;→ r0=r2-r1-C+1 Soustraction inversée avec retenue
AND r0,r1,r2 ;→ r0=r1&r2 Et binaire
ORR r0,r1,r2 ;→ r0=r1|r2 Ou binaire
EOR r0,r1,r2 ;→ r0=r1^r2 Ou exclusif binaire
BIC r0,r1,r2 ;→ r0=r1&~r2 Met à0 les bits de r1 indiqués par r2
Opérations de déplacement de données entre registres
OPE r_dest, r_s1
Exemples
MOV r0,r1 pour (r0=r1) ;Déplacement
MOV pc,lr pour (pc=lr) ;Déplacement
MVN r0,r1 pour (r0=~r1) ;Déplacement et négation
Opérations de décalage
OPE r_dest, r_s, r_m
Exemples
LSL r0,r1,r2 ;pour (r0=r1<<r2[7:0])
ASR r3,r4,r5 ;pour (r3=r4>>r5[7:0])
;Seul l’octet de poids faible de r_m est utilisé.
Les instructions
LSL ;→Décalage logique vers la gauche
LSR ;→Décalage logique vers la droite
ASL ;→Décalage arithmétique vers la gauche
ASR ;→Décalage arithmétique vers la droite
ROR ;→Décalage circulaire vers la droite
Modification des indicateur duPSR : Par défaut, les opérations arithmétiques et logiques nemodifient pas les indicateurs (N,Z,C,V) du PSR.Il faut ajouter le suffixe “S” au mnémonique de l’instruction.
Exemples
ADDS r0,r1,r2
ANDS r0,r1,r2
MOVS r0,r1
Tests et comparaisons
OPE r_s1, r_s2
Exemples
CMP r0,r1 ;pour (psr←r0−r1)
TEQ r0,r1 ;pour (psr←r0⊕r1)
Instructions
CMP r0,r1 ;→psr⇐r0-r1 Comparer
CMN r0,r1 ;→psr⇐r0+r1 Comparer à l’inverse
TST r0,r1 ;→psr⇐r0&r1 Tester les bits indiqués par r1
TEQ r0,r1 ;→psr⇐r0^r1 Tester l’égalité bit à bit
;Ces instructions ne modifient que les bits (N,Z,C,V) du PSR, le résultat n’est pas gardé.
Opérandes immédiats
Exemples
MOV r0,#0x20
CMP r0,#32
ADD r0,r1,#1
En mode ARM les instructions sont codées sur 32 bits et seulement 12 bits peuvent être utilisés pour coder l’immédiat.| Bit | 31 | 28 | 27 | 21 | 20 | 19 | 16 | 15 | 12 | 11 | 0 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Codage | cond | Code op | S | Rn | Rs | Imm | |||||
Exemples
ADD r0,r1,#100 ;(0x64<<0)
ADD r0,r1,#0xFF00 ;(0xFF<<8)
ADD r0,r1,#0x3FC ;(0xFF<<2)
ADD r0,r1,#0xF000000F ;(0xFF<<28)
ADD r0,r1,#0x102 Interdit!
Combiner une opération avec un décalage
Exemples
ADD r0,r1,r2,LSL #4 ;(r0=r1+r2×16)
ADD r0,r1,r2,LSL r3 ;(r0=r1+r2×2r3)
Les multiplications
Les instructions
MUL r0,r1,r2 →r0=r1xr2 multiplication
MLA r0,r1,r2,r3 →r0=r1+r2xr3 mult. et accumulation
MLS r0,r1,r2,r3 →r0=r1-r2xr3 mult. soustraction
UMULL r0,r1,r2,r3 →{r1,r0}=r2xr3 mult. 64bits non signée
SMULL r0,r1,r2,r3 →{r1,r0}=r2xr3 mult. 64bits signée
UMLAL r0,r1,r2,r3 →{r1,r0}+=r2xr3 MAC 64bits non signée
SMLAL r0,r1,r2,r3 →{r1,r0}+=r2xr3 MAC 64bits signée
Transfert de données depuis et vers la mémoire
Exemple
LDR r0,[r1] ;(r0=RAM[r1])
STR r0,[r1] ;(RAM[r1]=r0)
Taille des données
LDR/STR: mots de 32 bits (words)LDRH/STRH: mots de 16 bits (half words)
LDRB/STRB: mots de 16 bits (byte)
Généralement, les adressesdoivent être alignées :
LDR/STR: 4
LDRH/STRH: 2
LDRB/STRB: quelconque
Modes d’adressage
;Adressage indirect
LDR r0,[r1] ;(r0=RAM[r1])
;Adressage indirect avec déplacement(offset)
LDR r0,[r1,#8] ;(r0=RAM[r1+8])
LDR r0,[r1,r2] ;(r0=RAM[r1+r2])
;Adressage indirect avec déplacement et pré-incrémentation
LDR r0,[r1,#8]! ;(r1=r1+8 puis r0=RAM[r1])
;Adressage indirect avec déplacement et post-incrémentation
LDR r0,[r1],#8 ;(r0=RAM[r1] puis r1=r1+8)
Transferts multiples
Il existe 4 suffixes possibles pour les instructions de transferts multiples :Exemple
LDMIA r0,{r1,r2,r3} ;(r1 = RAM[r0])
;(r2 = RAM[r0 + 4])
;(r3 = RAM[r0 + 8])
STMIA r0,{r1-r3} ;(RAM[r0] = r1)
;(RAM[r0 + 4] = r2)
;(RAM[r0 + 8] = r3)
;Pour que la valeur du registre d’adresse soit modifiée il faut ajouter (!)
LDMIA r0!,{r1-r3}
la pile (stack)
Conventions
Le registre r13 (sp) est le pointeur de pile (stack pointer).Le pointeur de pile contient l’adresse de la dernière donnée empilée
Avant chaque empilement le pointeur de pile doit être décrémenté
La convention ARM standard est « Full Descending » commme beaucoup de processeur
Pour gérer la pile et éviter les confusions, il existe des équivalents des instructions LDM et STM avec des suffixes spécifiques en fonction des stratégies utilisées pour la pile.
Ou plus simplement :
;Empiler
PUSH {r1-r5} ou STMFD sp!,{r1-r5}
ou STMDB sp!,{r1-r5}
;Dépiler
POP {r1-r5} ou LDMFD sp!,{r1-r5}
ou LDMIA sp!,{r1-r5}
Contrôle de flot
Branchements
Il existe deux instructions de branchement :Exécution conditionnelle des instructions
L’exécution des instructions peut être rendue conditionnelle en rajoutant les suffixes suivant :Exemples
CMP r0,r1 ;comparer r0 à r1 SUBGE r0,r0,r1 ;si r0 ≥ r1 alors r0 = r0 - r1 SUBLT r0,r1,r0 ;si r0 < r1 alors r0 = r1 - r0 SUBS r0,r1,r2 ;r0 = r1 - r2 BEQ address ;aller à adresse si le résultat est nul
Exemples en assembleur
Start:
MOV r0,#0 @ mise zero de r0
MOV r2,#10 @ charger la valeur 10 dans r2
Loop:
ADD r0,r0,r2,LSL #1 @ r0=r0+2*r2
SUBS r2,r2,#1 @ r2--
BNE Loop
B Start
Pour débuter avec la Pilule Bleu (STM32)
LEDDELAY=0.0011111111111111s| Instruction | Description | Instruction | Description |
|---|---|---|---|
| MOV | Move data | EOR | Bitwise XOR |
| MVN | Move 2s complement | LDR | Load |
| ADD | Addition | STR | Store |
| SUB | Subtraction | LDM | Load Multiple |
| MUL | Multiplication | STM | Store Multiple |
| LSL | Logical Shift Left | PUSH | Push on Stack |
| LSR | Logical Shift Right | POP | Pop off Stack |
| ASR | Arithmetic Shift Right | B | Branch |
| ROR | Rotate Right | BL | Branch with Link |
| CMP | Compare | BX | Branch and eXchange |
| AND | Bitwise AND | BLX | Branch with Link and eXchange |
| ORR | Bitwise OR | SWI/SVC | System Call |
ldr RA,[RB] ;Opération LDR: charge la valeur trouvée à l'adresse RB dans le registre de destination RA.
str RA,[RB] ;Opération STR: stocke la valeur RA dans l'adresse de mémoire de RB.
ldr r0, adr_var1 @ charge l'adresse mémoire de var1 via l'étiquette adr_var1 dans R0
ldr r1, adr_var2 @ charger l'adresse mémoire de var2 via l'étiquette adr_var2 dans R1
ldr r2, [r0] @ charge la valeur trouvée à l'adresse mémoire de R0 dans le registre R2
str r2, [r1, #2] @ mode adresse: offset.
@ Stocke la valeur de R2 dans l'adresse de mémoire de R1+2.
@ Registre de base (R1) non modifié.
str r2, [r1, #4]! @ mode adresse: pré-indexé.
@ Stocke la valeur trouvée dans R2 dans l'adresse de mémoire de R1+4.
@ Registre de base (R1) modifié: R1=R1+4
ldr r3, [r1], #4 @ mode adresse: post-indexé.
@ Charge la valeur à l'adresse de mémoire de R1 dans le registre R3.
@ Registre de base (R1) modifié: R1 = R1 + 4
str r2, [r1, r2]! @ mode adresse: pré-indexé.
@ Stocke la valeur de R2 dans l’adresse mémoire de R1 avec l’offset R2.
@ Registre de base modifié: R1=R1+R2.
str r2, [r1, r2, LSL#2]! @ mode adresse: pré-indexé.
@ Stocke la valeur de R2 à l'adresse de mémoire de R1 avec le décalage R2 décalé à gauche de 2.
@ Registre de base modifié: R1=R1+R2<<2
Le Thumb
Le jeu d'instructions THUMB est un sous-ensemble de la liste complète des instructions ARM.La caractéristique des instructions THUMB est qu’elles ne sont que sur 16 bits.
En conséquence, une fonction dans THUMB peut être beaucoup plus courte que dans ARM, ce qui peut être bénéfique si vous ne disposez pas de beaucoup d'espace pour travailler.
Un autre point est que les instructions 16 bits traversent un bus de données 16 bits en une fois et sont exécutées immédiatement,
alors que l'exécution d'instructions 32 bits doit attendre que le second bloc soit récupéré, ce qui permet de réduire de moitié la vitesse d'instruction.
N'oubliez pas que ROM et EWEAM, les deux zones principales de code ont des bus 16 bits, c'est pourquoi les instructions THUMB sont conseillées pour la programmation GBA.
Il y a des inconvénients, bien sûr; vous ne pouvez pas simplement réduire de moitié la taille d'une instruction et vous attendre à vous en tirer.
Même si le code THUMB utilise plusieurs des mêmes mnémoniques que ARM, les fonctionnalités ont été considérablement réduites.
Par exemple, la seule instruction pouvant être conditionnelle est la branche, b; les instructions ne peuvent plus utiliser les décalages et les rotations (il s'agit maintenant d'instructions séparées),
et la plupart des instructions ne peuvent utiliser que les 8 registres les plus bas (r0-r7);
les plus élevés sont toujours disponibles, mais vous devez déplacer les éléments vers les plus bas car vous pouvez les utiliser.
En bref, écrire du code THUMB efficace est beaucoup plus difficile. Ce n'est pas exactement la programmation esclavage-disciple, mais si vous êtes habitué au jeu complet d'ARM, vous pourriez être surpris de temps en temps. THUMB utilise la plupart des mnémoniques d’ARM, mais bon nombre d’entre elles sont restreintes d’une manière ou d’une autre.
Apprendre à coder dans THUMB revient donc en gros à ce que vous ne pouvez plus faire. Dans cet esprit, cette section couvrira les différences entre ARM et THUMB, plutôt que le set THUMB lui-même.
ldr = Load Word (32 bits) ldrh = Load unsigned Half Word (16 bits) ldrsh = Load signed Half Word (signe + 15 bits) ldrb = Load unsigned Byte (8 bits) ldrsb = Load signed Bytes (signe + 7 bits) str = Store Word strh = Store unsigned Half Word (16 bits) strsh = Store signed Half Word (signe + 15 bits) strb = Store unsigned Byte (8 bits) strsb = Store signed Byte (signe + 7 bits)
Jeu d'instructions du Cortex M3
Correspondance entre les versions d'architectures et les familles de processeurs ARM
| Architecture | Famille |
|---|---|
| ARMv1 | ARM1 |
| ARMv2 | ARM2, ARM3 |
| ARMv3 | ARM6,ARM7 |
| ARMv4 | StrongARM, ARM7TDMI, ARM9 |
| ARMv5 | ARM7EJ, ARM9E, ARM10E, XScale |
| ARMv6 | ARM11, ARM Cortex-M |
| ARMv7 | ARM Cortex-A, ARM Cortex-M, ARM Cortex-R |
| ARMv8 | ARM Cortex-A50 |
Le Cortex M3 implémente un sous-ensemble du jeu d'instructions ARMv7-M ("M" pour "Microcontrôleur").
Ce jeu d'instruction utilise le codage Thumb-2, contenant le jeu simplifié Thumb codé sur 16 bits, et un ensemble de codes complémentaire sur 32 bits. La possibilité de mélanger librement les codes de 16 et 32 bits permet un gain d'efficacité par rapport au jeu original ARM de 32 bits et au Thumb.
1. Mnémoniques classés par catégories
Les instructions soulignées acceptent le suffixe S pour mise à jour des flags (NZCV).| Copie de données (32 bits) |
MOV de registre à registre ou immédiat vers registre LDR, STR Load (RAM vers registre), Store (registre vers RAM) LDM, STM Load et Store multiples (liste de registres), indirects PUSH, POP cas particuliers de STM et LDM |
| Copie et manipulation de byte (8 bits) et half-word (16 bits) |
LDR, STR avec suffixes B, H, SB, SH MOVT T=Top, affecte seulement les 16 MSBs REV permutation de bytes SXT, UXT extension à 32 bits signée ou non-signée (suff. B et H) |
| Manipulation de bits |
BFC, BFI, SBFX, UBFX bit fields (Clear, Insert, Extract) CLZ, RBIT comptage des zéros en tête, permutation de bits |
| Arithmétique |
ADD, ADC C=Carry (inclusion dans la somme) SUB, SBC, RSB C=Carry, R=reverse ( Rm-Rn au lieu de Rn-Rm ) MUL, MLA, MLS résultat modulo 2^32 (débordement possible), A=Accumulation UMULL, UMLAL résultat 64 bits (débordement impossible), A=Accumulation SMULL, SMLAL résultat 64 bits (débordement impossible), A=Accumulation SDIV, UDIV SSAT, USAT saturation taille arbitraire < 32 bits |
| Logique |
AND, BIC BIC = AND NOT ORR, ORN ORN = OR NOT EOR XOR MVN NOT |
| Décalages |
LSL, LSR, ASR, ROR décalage constant ou variable, de 1 à 31 positions RRX rotation de 1 position via le flag C |
| Tests sur data |
TST, TEQ comme ANDS et EORS mais resultat non conservé (pas de Rd) CMP, CMN comme SUBS et ADDS mais resultat non conservé (pas de Rd) CBZ, CBNZ Comparaison registre avec zéro puis branch |
| Sauts "Branch" |
B, BX X=Indirect BL, BLX L=Link (sauvegarde PC dans LR) CBZ, CBNZ Comparaison registre avec zéro puis branch TBB, TBH Table Branch : branchement indirect par table d'adresses |
| Divers |
NOP IT If-Then SVC interruption soft MSR, MRS accés au registre des flags WFE, WFI mise en veille ADR |
2. Syntaxe de codage des instructions
Suffixes des mnémoniques (collés sans espace) :
Registre destination
Le premier registre de la liste va recevoir le résultat, SAUF dans le cas STR (Store).Ce cas particulier est dû à un codage homogène pour LDR et STR :
LDR r0, [r1, #4] ; Load : registre <-- mémoire STR r0, [r1, #4] ; Store : registre --> mémoireLa seconde instruction fait l'opération inverse de la première.
Forme simplifiée 2 opérandes au lieu de 3
De nombreuses instructions prennent 2 opérandes sources et 1 opérande destination :ADD Rd, Rn, Rm ; Rd = Rn + RmSi on donne seulement 2 opérandes :
ADD Rd, Rm ; Rd = Rd + Rm soit Rd += Rml'assembleur met Rd à la position de Rn :
ADD Rd, Rd, Rm ; Rd += Rm
Modes d'adressage immediat ou littéral
{kind=link}
Modes d'adressage registre
Modes d'adressage mémoire
Instruction Branch
B unlabel ; un saut direct (codé en relatif) Bcc unlabel ; saut conditionnel, cc est une condition parmi les 14 possibles (voir suffixes ci-dessus) BL unlabel ; appel de sous programme (adresse retour copiée dans LR) BX r3 ; saut indirect par registre (par exemple r3) BX LR ; retour de sous programme simple BLX r3 ; appel de sous programme indirect par registre (adr retour dans LR) CBZ r0, label ; saut si r0 == 0 CBNZ r0, label ; saut si r0 != 0Notes :
Traitements conditionnels
Dans le jeu d'instructions ARM 32 bits, presque toutes les instructions peuvent être conditionnelles (ce qui encombre 4 bits dans l'encodage des instruction).Pour rendre le code plus compact, en Thumb-2 il n'y a que l'instruction B (Branch) qui contienne l'encodage d'une condition parmi les 14 possibles (voir suffixes ci-dessus). Cela couvre déjà la majorité des besoins en matière de traitement conditionnel.
Pour compenser, l'instruction spéciale IT (If-Then) a été ajoutée, elle permet de rendre conditionnelles 1 à 4 instructions consécutives :
movs r1, r1 ; l'assembleur insérera automatiquement l'instruction ite pl addpl r0, r1 submi r0, r1